Documentation Index Fetch the complete documentation index at: https://nvd-54.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
本指南涵盖将深度智能体从本地原型带入生产部署的注意事项。内容包括记忆范围划定、执行环境配置、添加护栏和连接前端。
智能体使用记忆和执行环境中的信息来完成任务。
在生产环境中,有几个基本概念决定了信息如何被共享和访问:
线程(Thread) :单次对话。消息历史和临时文件默认限定在线程范围内,不会跨线程延续。用户(User) :与智能体交互的人。记忆和文件可以是用户私有的,也可以跨用户共享。身份和授权来自你的认证层 。助手(Assistant) :已配置的智能体实例。记忆和文件可以绑定到一个助手,也可以跨所有助手共享。
本页面涵盖:
LangSmith Deployments 将深度智能体投入生产的最快方式是 deepagents deployLangSmith Deployment 。任何一种方式都会为你的智能体预置所需的基础设施:助手 、线程 、运行 、存储和检查点器,因此你无需自己设置。它还开箱即用地提供认证 、webhook 、定时任务 和可观测性 ,并可通过 MCP 或 A2A 暴露你的智能体。
有关基于 CLI 的方法,请参阅使用 CLI 部署 。有关手动设置,请参阅 LangSmith Deployments 快速入门 。
除非另有说明,本页面上的所有代码片段都使用以下 langgraph.json:
{ " dependencies " : [ "." ], " graphs " : { " agent " : "./agent.py:agent" }, " env " : ".env" }
langgraph.json 是告诉 LangGraph 平台如何构建和运行你的应用程序的配置文件。它位于项目根目录,本地开发(使用 langgraph dev)和生产部署都需要它。关键字段包括:字段 描述 dependencies要安装的包。["."] 将当前目录作为包安装(从 requirements.txt、pyproject.toml 或 package.json 读取)。 graphs将图 ID 映射到其代码位置。每个条目是 "<id>": "./<file>:<variable>",其中 <id> 是你通过 API 调用图时使用的名称,<variable> 是从 <file> 导出的已编译图或构造函数。 env包含环境变量(API 密钥、秘密)的 .env 文件路径。这些在构建时设置,在运行时可用。
有关完整的配置选项(自定义 Docker 步骤、存储索引、认证处理器等),请参阅应用结构 。
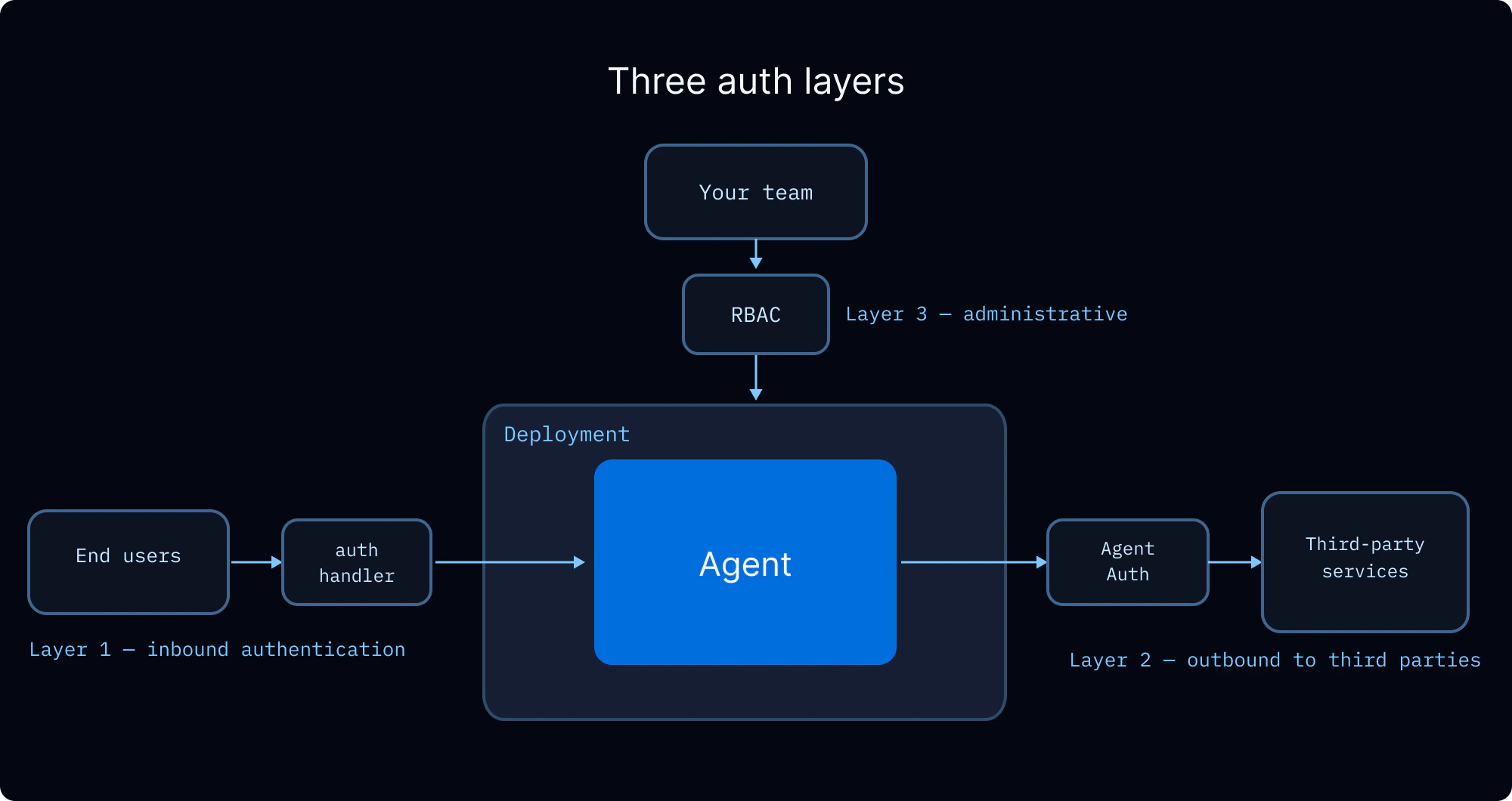
生产注意事项 多租户 当你的智能体服务多个用户时,你需要处理三个关注点:验证每个用户的身份、控制他们能访问什么,以及管理智能体代表用户使用的凭证。
用户身份和访问控制 LangSmith Deployments 支持自定义认证 来建立用户身份,以及授权处理器 来控制对线程、助手和存储命名空间等资源的访问。授权处理器在认证成功后运行,可以:
用所有权元数据标记资源(例如 owner: user_id)
返回过滤器,使用户只能看到自己的资源
对未授权操作返回 HTTP 403 拒绝访问
有关分步教程,请参阅使对话私有化 。有关演练,观看自定义认证视频 。
你如何划定记忆范围 和执行环境 决定了用户之间共享哪些数据。详情请参阅以下章节。
团队访问控制 (RBAC) LangSmith 的基于角色的访问控制 管理你团队中谁可以部署、配置和监控智能体。这与上述的终端用户授权是分开的。
角色 访问权限 工作区管理员 完整权限,包括设置和成员管理 工作区编辑者 创建和修改资源,但无法删除运行或管理成员 工作区查看者 只读访问
企业版提供具有细粒度权限的自定义角色。有关完整的权限模型,请参阅 RBAC 参考 。
终端用户凭证 当你的智能体需要代表用户调用外部 API(例如读取他们的 GitHub 仓库、发送 Slack 消息、查询他们的数据仓库)时,你需要一种将用户凭证传递给智能体的方式,而不是硬编码它们。
通过 Agent Auth 的 OAuth。 Agent Auth 提供托管的 OAuth 2.0 流程。配置 OAuth 提供商,智能体即可请求限定到每个用户的 Token。首次使用时,智能体会中断 执行并呈现 OAuth 同意 URL。用户认证后,智能体以有效 Token 恢复执行。Token 会自动存储和刷新。from langchain_auth import Client from langchain . tools import tool , ToolRuntime auth_client = Client () # 在你的智能体的工具中: @tool async def github_action ( runtime : ToolRuntime ): """代表用户在 GitHub 上执行操作。""" auth_result = await auth_client . authenticate ( provider = "github" , scopes = [ "repo" , "read:org" ], user_id = runtime . server_info . user . identity , ) # 使用 auth_result.token 代表用户调用 GitHub API
沙箱的凭证注入。 如果你的智能体在调用外部 API 的沙箱 中运行代码,沙箱认证代理 可以自动将凭证注入到出站请求中,使沙箱代码永远不会接触到原始 API 密钥。详情请参阅管理秘密 。工作区秘密。 对于跨所有用户共享的 API 密钥(例如你组织的大语言模型(LLM)提供商密钥、搜索 API 密钥),将它们存储为 LangSmith 中的工作区秘密 。详情请参阅管理秘密 。基于大语言模型(LLM)的应用是高度 I/O 密集型的:调用语言模型、数据库和外部服务。异步编程让这些操作可以并发运行而非阻塞,提高吞吐量和响应能力。
LangChain 遵循在异步方法名前加 a 前缀的约定(例如 ainvoke、abefore_agent、astream)。同步和异步变体位于同一个类或命名空间中。
为生产环境构建时:
创建异步工具。 LangChain 在单独的线程中运行同步工具以避免阻塞,但原生异步完全避免了线程开销。使用异步中间件方法。 自定义中间件 应实现异步钩子(例如 abefore_agent 而非 before_agent)。对外部资源生命周期使用异步。 创建沙箱 或连接 MCP 服务器 涉及网络调用,应使用 await。这就是为什么预置这些资源的图工厂 是异步的。
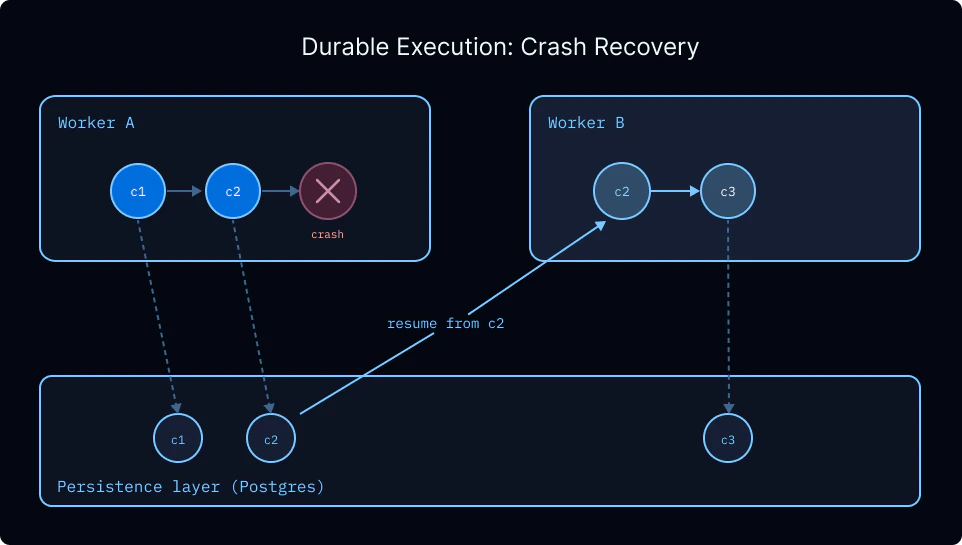
持久性 深度智能体运行在 LangGraph 上,它开箱即用地提供持久执行 。持久化 层在每一步都会创建检查点,因此被故障、超时或人机协作 暂停中断的运行会从上次记录的状态恢复,无需重新处理之前的步骤。对于产生大量子智能体的长时间运行深度智能体,这意味着中途故障不会丢失已完成的工作。
检查点还支持:
无限期中断 。 人机协作工作流可以暂停几分钟或几天,然后从中断的位置精确恢复。时间旅行 。安全处理敏感操作。 对于涉及支付或其他不可逆操作的工作流,检查点提供了审计追踪和恢复点,可以检查导致操作的确切状态。
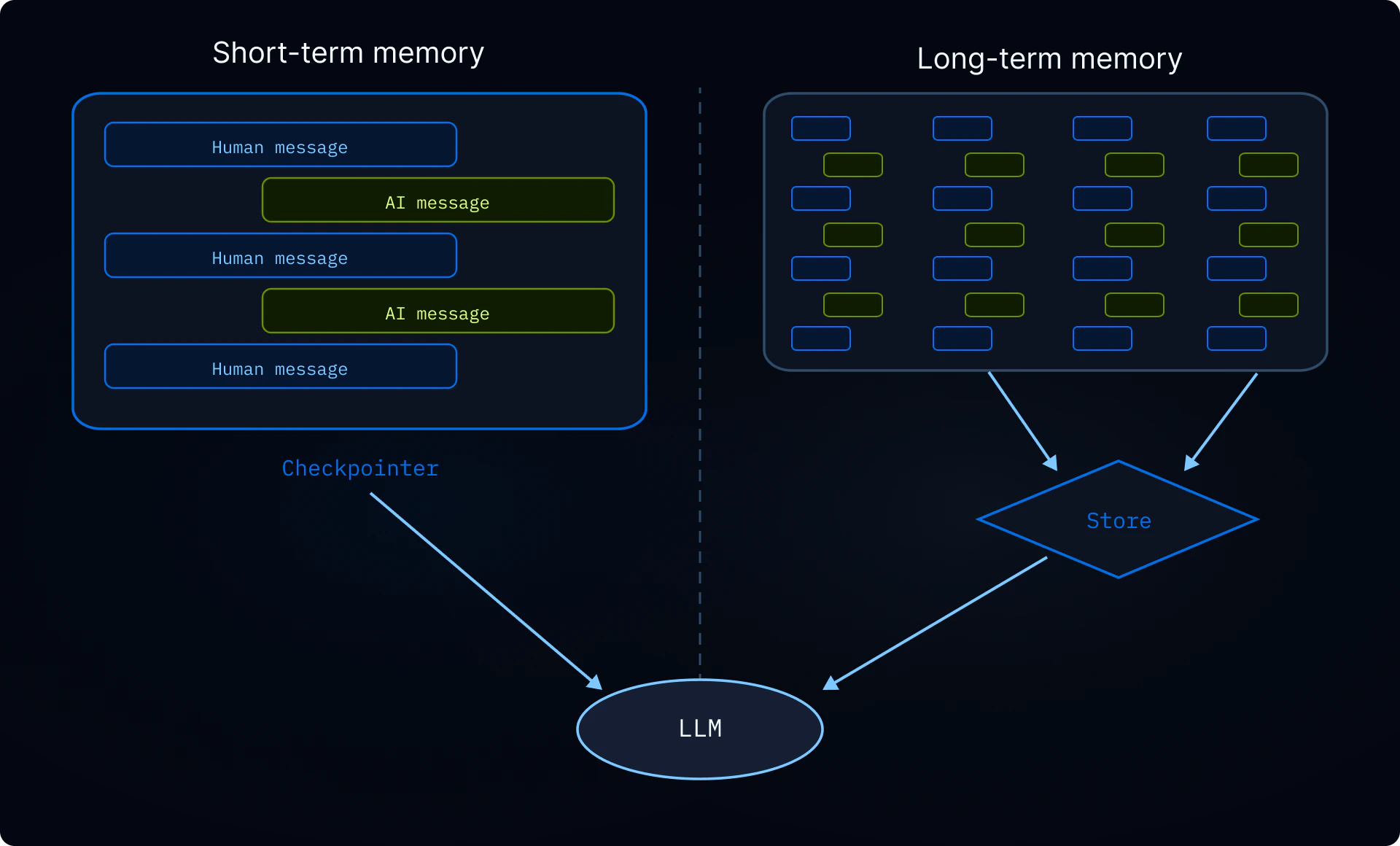
没有记忆,每次对话都从头开始。记忆让你的智能体能在对话之间保留信息(用户偏好、学到的指令、过往经验),从而随时间个性化其行为。有关记忆类型的概述,请参阅记忆概念指南 。
范围划定 记忆始终跨对话持久化。主要问题是它如何在用户和助手边界之间划定范围。正确的范围取决于谁应该查看和修改数据:
范围 命名空间 用例 示例 用户 (推荐默认)(user_id)每个用户的偏好和上下文 ”我喜欢简洁的回复” 助手 (assistant_id)一个助手的共享指令 ”帖子限制在 280 个字符” 全局 (org_id)所有用户和助手的只读策略 ”不要公开内部定价”
共享记忆(助手、用户或组织范围)是提示注入的攻击向量。如果一个用户可以写入另一个用户对话读取的记忆,恶意用户可以向该共享状态注入指令。在适当的地方强制执行只读访问。例如,使组织范围的策略只能通过应用程序代码写入,而非智能体本身。使用权限 以声明式方式拒绝对共享路径的写入,或使用后端策略钩子 实现自定义验证逻辑。 在深度智能体中,记忆作为文件存储在虚拟文件系统中。默认情况下,文件限定在单个线程(对话)范围内,不跨线程共享。要跨线程共享记忆,请将 /memories/ 等路径路由到写入 LangGraph Store 的 StoreBackend 。使用 CompositeBackend 为智能体提供线程范围的临时空间和跨线程的长期记忆 。
下面显示的 rt.server_info 和 rt.execution_info 命名空间模式需要 deepagents>=0.5.0。
按 user_id 划分命名空间。每个用户获得自己的私有记忆。这是推荐的默认方式,因为大多数应用程序部署单个助手。 from deepagents import create_deep_agent from deepagents . backends import CompositeBackend , StateBackend , StoreBackend agent = create_deep_agent ( model = "google_genai:gemini-3.1-pro-preview" , backend = CompositeBackend ( default = StateBackend (), routes = { "/memories/" : StoreBackend ( namespace = lambda rt : ( rt . server_info . assistant_id , rt . server_info . user . identity , ), ), }, ), system_prompt = """You have persistent memory at /memories/. Read /memories/instructions.txt at the start of each conversation for accumulated knowledge and preferences. When you learn something that should persist, update that file.""" , )
按 assistant_id 划分命名空间。记忆在同一助手的所有用户之间共享,因此任何用户都可以读取或更新它。用于适用于使用特定助手的所有人的共享指令或知识(例如”始终以正式语气回复”)。 from deepagents import create_deep_agent from deepagents . backends import CompositeBackend , StateBackend , StoreBackend agent = create_deep_agent ( model = "google_genai:gemini-3.1-pro-preview" , backend = CompositeBackend ( default = StateBackend (), routes = { "/memories/" : StoreBackend ( namespace = lambda rt : ( rt . server_info . assistant_id , ), ), }, ), )
仅按 user_id 划分命名空间。记忆跟随用户跨所有助手。用于全局用户资料(姓名、时区、沟通偏好),应适用于用户与之交谈的任何助手。 from deepagents import create_deep_agent from deepagents . backends import CompositeBackend , StateBackend , StoreBackend agent = create_deep_agent ( model = "google_genai:gemini-3.1-pro-preview" , backend = CompositeBackend ( default = StateBackend (), routes = { "/memories/" : StoreBackend ( namespace = lambda rt : ( rt . server_info . user . identity ,), ), }, ), )
按 org_id 划分命名空间。记忆在所有用户和所有助手之间共享。通常用于组织范围的策略(合规规则、品牌指南),对智能体应为只读。写入权限应限制在应用程序代码,以防止提示注入。 from deepagents import create_deep_agent from deepagents . backends import CompositeBackend , StateBackend , StoreBackend agent = create_deep_agent ( model = "google_genai:gemini-3.1-pro-preview" , backend = CompositeBackend ( default = StateBackend (), routes = { "/memories/" : StoreBackend ( namespace = lambda rt : ( rt . context . org_id ,), ), }, ), )
你也可以使用 Store API 从应用程序代码读写存储。参阅高级用法 了解示例。
有关完整的命名空间工厂 API,请参阅命名空间工厂 。有关自我改进指令和知识库等记忆模式,请参阅长期记忆 。
执行环境 在本地,智能体可以在磁盘上读写文件并直接运行 shell 命令。在生产环境中,你需要考虑隔离和持久化。正确的设置取决于你的智能体是否需要执行代码:
文件系统后端 ——如果你的智能体只需要读写文件就够了。选择一个匹配你持久化需求的后端:线程范围的临时空间、跨线程存储,或两者的混合。沙箱 ——添加一个带有 execute 工具的隔离容器来运行 shell 命令。如果你的智能体需要运行代码、安装包或执行文件 I/O 以外的操作,请使用沙箱。
文件系统 根据需要持久化的内容选择后端:
有关后端的完整列表以及如何构建自定义后端,请参阅后端 。
FilesystemBackend 和 LocalShellBackend 直接访问主机。不要在已部署的智能体中使用它们。
如果你的智能体需要运行代码(不仅仅是读写文件),请使用沙箱 。沙箱提供文件系统和用于在隔离容器中运行 shell 命令的 execute 工具。这种隔离也保护你的主机:如果智能体的代码耗尽内存或崩溃,只有沙箱受到影响。你的服务器继续运行。
生命周期 关键决策是沙箱的存活时间。每次对话获得一个全新的沙箱,还是对话共享一个持久环境?
范围 沙箱 ID 存储在 生命周期 示例用例 线程范围 线程 元数据每次对话新建,TTL 过期后清理 数据分析机器人,每次对话从零开始 助手范围 助手 配置跨所有对话共享 编码助手,维护跨对话的克隆仓库
以下示例使用异步图工厂 而非静态图,因为沙箱需要 thread_id 或 assistant_id 来查找或创建正确的沙箱。图工厂不接收完整的 Runtime(没有 server_info 或 execution_info);而是接受 RunnableConfig 并从 config["configurable"] 读取 thread_id 和 assistant_id。工厂是异步的,因为沙箱创建是一个 I/O 密集型操作,需要仅在调用时可用的每次运行信息。 每次对话获得自己的沙箱。图工厂 从运行配置中读取 thread_id,因此每个线程 自动获得自己的隔离环境。提供商基于标签的查找处理去重。沙箱 TTL 过期时清理。 from daytona import CreateSandboxFromSnapshotParams , Daytona from deepagents import create_deep_agent from langchain_core . runnables import RunnableConfig from langchain_daytona import DaytonaSandbox client = Daytona () async def agent ( config : RunnableConfig ): thread_id = config [ " configurable " ][ "thread_id" ] try : sandbox = await client . find_one ( labels = { "thread_id" : thread_id }) except Exception : sandbox = await client . create ( CreateSandboxFromSnapshotParams ( labels = { "thread_id" : thread_id }, auto_delete_interval = 3600 , # TTL: clean up when idle ) ) return create_deep_agent ( model = "google_genai:gemini-3.1-pro-preview" , backend = DaytonaSandbox ( sandbox = sandbox ) )
所有对话共享一个沙箱。图工厂 从 config["configurable"] 读取助手 ID,因此同一助手上的每个线程都返回到相同的环境。文件、已安装的包和克隆的仓库跨对话持久化。 from daytona import CreateSandboxFromSnapshotParams , Daytona from deepagents import create_deep_agent from langchain_core . runnables import RunnableConfig from langchain_daytona import DaytonaSandbox client = Daytona () async def agent ( config : RunnableConfig ): assistant_id = config [ " configurable " ][ "assistant_id" ] try : sandbox = await client . find_one ( labels = { "assistant_id" : assistant_id }) except Exception : sandbox = await client . create ( CreateSandboxFromSnapshotParams ( labels = { "assistant_id" : assistant_id }) ) return create_deep_agent ( model = "google_genai:gemini-3.1-pro-preview" , backend = DaytonaSandbox ( sandbox = sandbox ) )
助手范围的沙箱会随时间积累文件、已安装的包和其他沙箱内状态。配置提供商的 TTL,使用快照定期重置,或实现清理逻辑以防止沙箱的磁盘和内存无限增长。
因为 agent 变量是异步函数(不是已编译的图),服务器将其视为图工厂 并在每次运行时调用它,注入配置。工厂通过提供商基于标签的搜索查找或创建沙箱,并返回连接到该沙箱的新智能体图。
使用 langgraph deploy 部署后,使用 SDK 从应用程序代码调用智能体。客户端代码无论范围如何都是相同的。范围完全在上面的智能体工厂中处理,但行为不同:
每个线程获得自己的沙箱。同一线程内的后续消息复用同一个沙箱,但新线程总是以没有之前对话遗留文件或已安装包的干净环境开始。 from langgraph_sdk import get_client client = get_client ( url = "<DEPLOYMENT_URL>" , api_key = "<LANGSMITH_API_KEY>" ) # 对话 1:安装 pandas 并分析数据 thread_1 = await client . threads . create () async for chunk in client . runs . stream ( thread_1 [ " thread_id " ], "agent" , input = { "messages" : [{ "role" : "human" , "content" : "Install pandas and analyze sales_data.csv" }]}, stream_mode = "updates" , ): print ( chunk . data ) # 同一对话的后续——pandas 仍已安装 async for chunk in client . runs . stream ( thread_1 [ " thread_id " ], "agent" , input = { "messages" : [{ "role" : "human" , "content" : "Now plot the results" }]}, stream_mode = "updates" , ): print ( chunk . data ) # 对话 2:全新沙箱——pandas 未安装,没有对话 1 的文件 thread_2 = await client . threads . create () async for chunk in client . runs . stream ( thread_2 [ " thread_id " ], "agent" , input = { "messages" : [{ "role" : "human" , "content" : "What packages are installed?" }]}, stream_mode = "updates" , ): print ( chunk . data )
所有线程共享一个沙箱。当沙箱有状态需要昂贵的重建(如克隆的仓库、已安装的依赖或构建产物)时很有用。同一助手上的任何对话都可以从上一次中断的地方继续,无需重复设置。 from langgraph_sdk import get_client client = get_client ( url = "<DEPLOYMENT_URL>" , api_key = "<LANGSMITH_API_KEY>" ) # 对话 1:克隆并设置项目 thread_1 = await client . threads . create () async for chunk in client . runs . stream ( thread_1 [ " thread_id " ], "agent" , input = { "messages" : [{ "role" : "human" , "content" : "Clone https://github.com/org/repo and install dependencies" }]}, stream_mode = "updates" , ): print ( chunk . data ) # 对话 2:仓库和依赖仍在 thread_2 = await client . threads . create () async for chunk in client . runs . stream ( thread_2 [ " thread_id " ], "agent" , input = { "messages" : [{ "role" : "human" , "content" : "Run the test suite and fix any failures" }]}, stream_mode = "updates" , ): print ( chunk . data )
文件传输 沙箱是隔离容器,因此你的应用程序代码无法直接访问其中的文件。使用 upload_files() 和 download_files() 在沙箱边界之间移动数据:
在智能体运行前为沙箱准备数据 :上传用户文件、技能 脚本、配置或持久化记忆 ,使智能体从一开始就拥有所需的内容在智能体完成后检索结果 :下载生成的产物(报告、图表、导出文件)并将更新的记忆同步回去以供未来对话使用
有关特定提供商的文件传输示例,请参阅使用文件 。有关提供商设置、安全性和生命周期模式,请参阅完整的沙箱指南 。
智能体需要执行的技能 脚本必须在智能体运行前上传到沙箱中。你可能还想同步记忆 ,以便智能体可以在容器内读取和更新它们。使用带有 before_agent 和 after_agent 钩子的自定义中间件 在沙箱边界之间移动文件: from deepagents import create_deep_agent from langchain . agents . middleware import AgentMiddleware , AgentState from langgraph . runtime import Runtime def _safe_filename ( key : str ) -> str : """拒绝包含路径遍历或通配符的键。""" name = key . split ( "/" )[ - 1 ] if ".." in name or any ( c in name for c in ( "*" , "?" )): raise ValueError ( f "Invalid key: { key } " ) return name class SandboxSyncMiddleware ( AgentMiddleware ): """在存储和沙箱之间同步技能和记忆。""" def __init__ ( self , backend : CompositeBackend ): super (). __init__ () self . backend = backend async def abefore_agent ( self , state : AgentState , runtime : Runtime ) -> None : """将技能脚本和记忆上传到沙箱。""" user_id = runtime . server_info . user . identity store = runtime . store files = [] for item in await store . asearch (( "skills" , user_id )): name = _safe_filename ( item . key ) files . append (( f "/skills/ { name } " , item . value [ " content " ]. encode ())) for item in await store . asearch (( "memories" , user_id )): name = _safe_filename ( item . key ) files . append (( f "/memories/ { name } " , item . value [ " content " ]. encode ())) if files : await self . backend . upload_files ( files ) async def aafter_agent ( self , state : AgentState , runtime : Runtime ) -> None : """将更新的记忆同步回存储。""" user_id = runtime . server_info . user . identity store = runtime . store items = await store . asearch (( "memories" , user_id )) results = await self . backend . download_files ( [ f "/memories/ { item . key } " for item in items ] ) for result in results : if result . content is not None : await store . aput ( ( "memories" , user_id ), result . path . split ( "/" )[ - 1 ], { "content" : result . content . decode ()}, ) backend = CompositeBackend ( default = DaytonaSandbox ( sandbox = sandbox ), routes = { "/skills/" : StoreBackend ( rt , namespace = lambda rt : ( "skills" , rt . server_info . user . identity ), ), "/memories/" : StoreBackend ( rt , namespace = lambda rt : ( "memories" , rt . server_info . user . identity ), ), }, ) agent = create_deep_agent ( model = "google_genai:gemini-3.1-pro-preview" , backend = backend , middleware = [ SandboxSyncMiddleware ( backend )], )
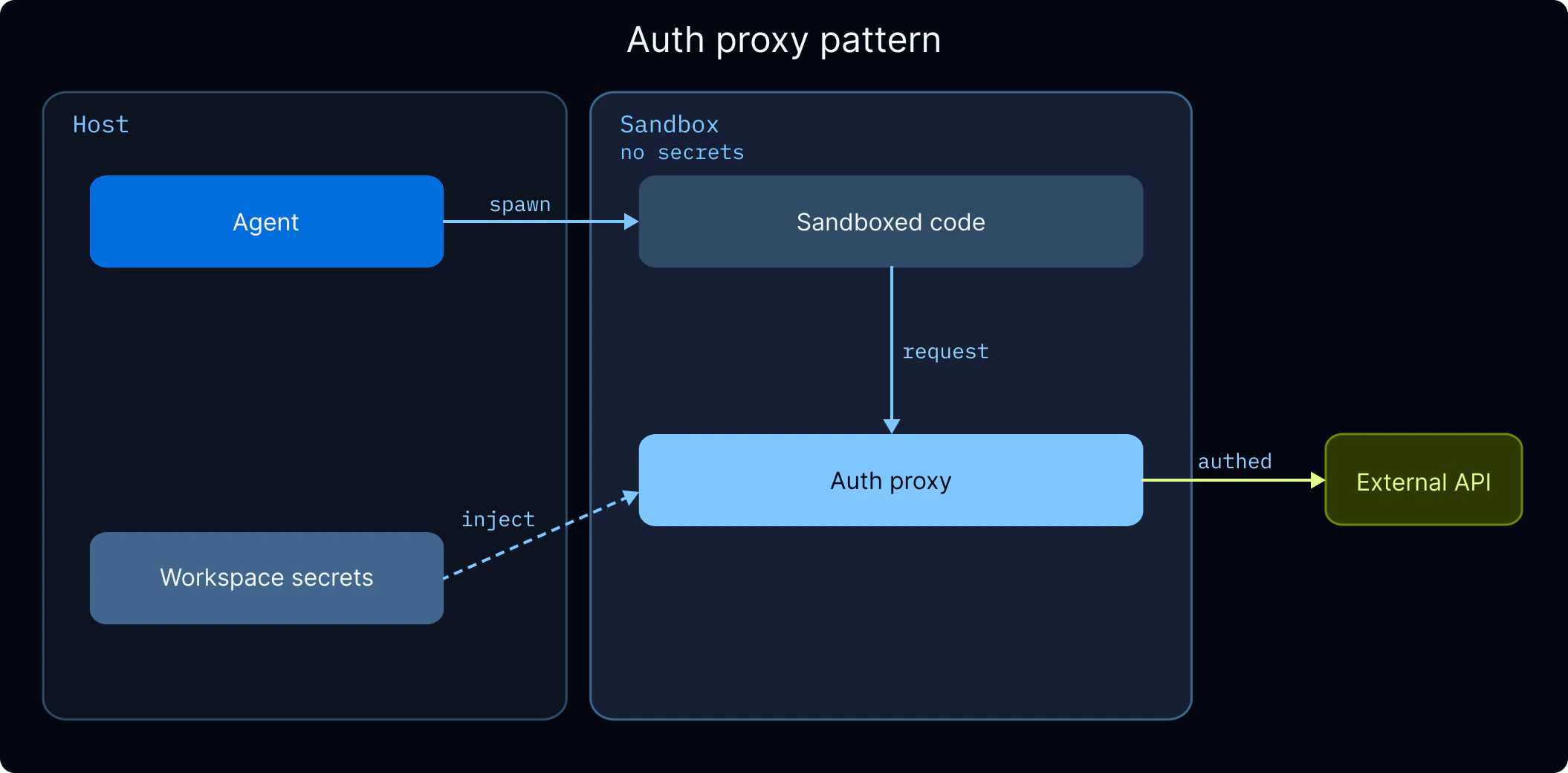
管理秘密 沙箱是隔离容器,因此你主机上的环境变量在其中不可用。有两种方式为沙箱代码提供 API 密钥和其他秘密:
认证代理(推荐)。 沙箱认证代理 拦截来自沙箱的出站请求并自动注入认证头。沙箱代码正常调用外部 API,代理根据目标主机添加正确的凭证。这意味着 API 密钥永远不会出现在沙箱代码、环境变量或日志中。{ " proxy_config " : { " rules " : [ { " name " : "openai-api" , " match_hosts " : [ "api.openai.com" ], " inject_headers " : { " Authorization " : "Bearer ${OPENAI_API_KEY}" } }, { " name " : "anthropic-api" , " match_hosts " : [ "api.anthropic.com" ], " inject_headers " : { " x-api-key " : "${ANTHROPIC_API_KEY}" } } ] } }
${SECRET_KEY} 引用在 LangSmith 工作区设置 中存储的秘密进行解析。在创建引用它们的模板之前,请先在那里配置秘密。工作区秘密。 对于不需要基于代理注入的 API 密钥(例如智能体服务器本身使用的密钥,而非沙箱代码),将它们存储为 LangSmith 中的工作区秘密 。这些作为环境变量在工作区中所有智能体的运行时可用。避免通过环境变量或文件上传将秘密传入沙箱。智能体可以读取沙箱内的任何可访问文件或环境变量,包括凭证。认证代理完全将秘密隔离在沙箱外。
生产中的智能体自主运行,这意味着它们可能无限循环、触及速率限制,或处理包含敏感信息的用户数据。深度智能体提供两层保护:
权限 中间件
速率限制 这里的速率限制指的是限制智能体在运行中自身的大语言模型(LLM)和工具使用量,而非入站请求的 API 网关速率限制。
没有限制,困惑的智能体可能在几分钟内通过循环相同的工具调用或进行数百次模型调用耗尽你的大语言模型(LLM)API 预算。对每次运行中的模型调用和工具执行都设置上限:
from deepagents import create_deep_agent from langchain . agents . middleware import ModelCallLimitMiddleware , ToolCallLimitMiddleware agent = create_deep_agent ( model = "google_genai:gemini-3.1-pro-preview" , middleware = [ ModelCallLimitMiddleware ( run_limit = 50 ), ToolCallLimitMiddleware ( run_limit = 200 ), ], )
使用 run_limit 限制单次调用中的调用数(每轮重置)。使用 thread_limit 限制整个对话中的调用数(需要检查点器)。参阅 ModelCallLimitMiddleware 和 ToolCallLimitMiddleware 了解完整配置。
处理错误 不是所有错误都应该以相同方式处理。瞬时故障(网络超时、速率限制)应自动重试。大语言模型(LLM)可以恢复的错误(错误的工具输出、解析失败)应反馈给模型。需要人工输入的错误应暂停智能体。有关完整分类和代码示例,请参阅适当处理错误 。
中间件处理瞬时情况。模型调用和工具调用各自有带有指数退避的重试中间件。如果你的主要模型提供商完全宕机,回退中间件会切换到替代方案:
from deepagents import create_deep_agent from langchain . agents . middleware import ( ModelFallbackMiddleware , ModelRetryMiddleware , ToolRetryMiddleware , ) agent = create_deep_agent ( model = "google_genai:gemini-3.1-pro-preview" , middleware = [ # 在速率限制、超时和 5xx 错误时重试模型调用 ModelRetryMiddleware ( max_retries = 3 , backoff_factor = 2.0 , initial_delay = 1.0 ), # 如果主模型完全宕机,回退到替代方案 ModelFallbackMiddleware ( "gpt-5.4" ), # 重试调用外部 API 的特定工具(不是所有工具) ToolRetryMiddleware ( max_retries = 2 , tools = [ "search" , "fetch_url" ], retry_on = ( TimeoutError , ConnectionError ), ), ], )
将 ToolRetryMiddleware 限定到特定工具,而非重试所有工具。文件系统的 read_file 失败不会因重试而受益,但超时的网络搜索可能会。参阅 ModelRetryMiddleware 和 ModelFallbackMiddleware 了解完整配置。
数据隐私 如果你的智能体处理可能包含邮箱、信用卡号或其他 PII 的用户输入,你可以在它到达模型或存入日志之前检测和处理它:
from deepagents import create_deep_agent from langchain . agents . middleware import PIIMiddleware agent = create_deep_agent ( model = "google_genai:gemini-3.1-pro-preview" , middleware = [ PIIMiddleware ( "email" , strategy = "redact" , apply_to_input = True ), PIIMiddleware ( "credit_card" , strategy = "mask" , apply_to_input = True ), ], )
策略包括 redact(替换为 [REDACTED_EMAIL])、mask(部分遮盖如 ****-****-****-1234)、hash(确定性哈希)和 block(抛出错误)。你也可以为领域特定的模式编写自定义检测器。
参阅 PIIMiddleware 了解完整配置。
有关可用中间件的完整列表,请参阅预置中间件 。
深度智能体使用 useStreamuseStream 是一个前端钩子(适用于 React、Vue、Svelte 和 Angular),可从智能体实时流式传输消息、子智能体进度和自定义状态。
在本地,useStream 指向 http://localhost:2024。在生产环境中,将其指向你的 LangSmith Deployment 并配置重连,使用户在连接断开时不会丢失进度。
import { useStream } from "@langchain/react" ; function App () { const stream = useStream < typeof agent > ( { apiUrl : "https://your-deployment.langsmith.dev" , assistantId : "agent" , reconnectOnMount : true , // 页面刷新或导航后恢复流 fetchStateHistory : true , // 挂载时加载完整的线程历史 } ) ; }
reconnectOnMount 自动接续正在进行的运行。如果用户在智能体工作时刷新页面,他们会看到它继续执行而非空白屏幕。fetchStateHistory 加载线程的完整对话历史,使返回的用户能看到之前的消息。对于产生大量子智能体的深度智能体工作流,在提交时设置较高的 recursionLimit 以避免截断长时间运行的执行:
stream . submit ( { messages : [ { type : "human" , content : text } ] }, { streamSubgraphs : true , config : { recursionLimit : 10000 }, }, ) ;
有关深度智能体特定的 UI 模式,如子智能体卡片、待办列表和自定义状态渲染,请参阅前端指南 。
连接这些文档 到 Claude、VSCode 等工具,通过 MCP 获取实时解答。