

上下文工程是以正确的格式提供正确的信息和工具,使深度智能体能够可靠地完成任务。 深度智能体可以访问多种上下文。一些来源在启动时提供给智能体;其他来源在运行时变得可用,例如用户输入。深度智能体包含内置机制来管理长时间运行会话中的上下文。 本页概述了深度智能体可访问和管理的不同类型的上下文。Documentation Index
Fetch the complete documentation index at: https://nvd-54.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
上下文类型
输入上下文
输入上下文是在启动时提供给深度智能体的信息,成为其系统提示词的一部分。最终提示词由多个来源组成:系统提示词
你提供的自定义指令加上内置的智能体指导。
记忆
配置后始终加载的持久
AGENTS.md 文件。技能
相关时按需加载的能力(渐进式披露)。
工具提示词
使用内置工具或自定义工具的说明。
系统提示词
你的自定义系统提示词会被添加到内置系统提示词之前,内置提示词包含规划、文件系统工具和子智能体的指导。使用它来定义智能体的角色、行为和知识:system_prompt 参数是静态的,这意味着它不会在每次调用时改变。
对于某些用例,你可能需要动态提示词:例如,告诉模型”你有管理员权限”与”你有只读权限”,或从长期记忆注入用户偏好如”用户偏好简洁回复”。
如果你的提示词依赖于上下文或 runtime.store,使用 @dynamic_prompt 构建上下文感知的指令。你的中间件可以读取 request.runtime.context 和 request.runtime.store。
参见自定义了解添加自定义中间件,以及 LangChain 上下文工程指南中的示例。
当仅工具使用上下文或 runtime.store 时,你不需要中间件;工具直接接收 ToolRuntime 对象(包括 runtime.context 和 runtime.store)。仅在工具应与系统提示词更新打包在一起时才添加中间件。
记忆
记忆文件(AGENTS.md)提供始终加载到系统提示词的持久上下文。将记忆用于项目约定、用户偏好和应适用于每次对话的关键准则:
技能
技能提供按需能力。智能体在启动时读取每个SKILL.md 的 frontmatter,然后仅在确定技能相关时才加载完整的技能内容。这在提供专门工作流的同时减少了 Token 使用:
工具提示词
工具提示词是塑造模型如何使用工具的指令。所有工具都暴露模型在其提示词中看到的元数据——通常是模式和描述。你通过tools 参数传递的工具会将其工具元数据(模式和描述)呈现给模型。深度智能体的内置工具打包在中间件中,通常还会用更多指导更新系统提示词。
内置工具 — 添加 Harness 能力(规划、文件系统、子智能体)的中间件会自动将工具特定的指令追加到系统提示词,创建解释如何有效使用这些工具的工具提示词:
- 规划提示词 —
write_todos维护结构化任务列表的指令 - 文件系统提示词 —
ls、read_file、write_file、edit_file、glob、grep(以及使用沙箱后端时的execute)的文档 - 子智能体提示词 — 使用
task工具委派工作的指导 - 人机协作提示词 — 在指定的工具调用处暂停的用法(当设置了
interrupt_on时) - 本地上下文提示词 — 当前目录和项目信息(仅 CLI)
tools 参数传递的工具会将其描述(来自工具模式)发送给模型。你还可以添加自定义中间件来添加工具并追加自己的系统提示词指令。
对于你提供的工具,请确保提供清晰的名称、描述和参数描述。这些指导模型推理何时以及如何使用工具。在描述中包含何时使用工具,并描述每个参数的作用。
完整系统提示词
深度智能体的系统消息——模型在运行开始时收到的组装后的系统提示词——由以下部分组成:- 自定义
system_prompt(如果提供) - 基础智能体提示词
- 待办列表提示词:如何使用待办列表进行规划的指令
- 记忆提示词:
AGENTS.md+ 记忆使用指南(仅在提供memory时) - 技能提示词:技能位置 + 带 frontmatter 信息的技能列表 + 用法(仅在提供技能时)
- 虚拟文件系统提示词(文件系统 + execute 工具文档(如适用))
- 子智能体提示词:task 工具用法
- 用户提供的中间件提示词(如果提供了自定义中间件)
- 人机协作提示词(当设置了
interrupt_on时)
运行时上下文
运行时上下文是你在调用智能体时传递的每次运行配置。它不会自动包含在模型提示词中;模型仅在工具、中间件或其他逻辑读取它并将其添加到消息或系统提示词时才能看到它。将运行时上下文用于用户元数据(ID、偏好、角色)、API 密钥、数据库连接、功能标志或工具和 Harness 需要的其他值。 使用context_schema 定义数据形状:使用 dataclasses.dataclass 或 typing.TypedDict 类。使用 invoke / ainvoke 的 context 参数传递值。参见 Runtime 和 LangGraph 运行时上下文了解完整详情。
在工具内部,从注入的 ToolRuntime 读取上下文:
上下文压缩
长时间运行的任务会产生大量工具输出和较长的对话历史。上下文压缩在保留与任务相关的细节的同时减少智能体工作记忆中的信息量。以下技术是确保传递给大语言模型(LLM)的上下文保持在其上下文窗口限制内的内置机制:卸载
大型工具输入和结果存储到文件系统中,并替换为引用。
摘要
当接近限制时,旧消息被压缩为大语言模型(LLM)生成的摘要。
卸载
深度智能体使用内置文件系统工具自动卸载内容,并在需要时搜索和检索卸载的内容。当工具调用的输入或结果超过 Token 阈值(默认 20,000)时会触发内容卸载:-
工具调用输入超过 20,000 Token:文件写入和编辑操作会在智能体的对话历史中留下包含完整文件内容的工具调用。由于此内容已持久化到文件系统,通常是冗余的。当会话上下文超过模型可用窗口的 85% 时,深度智能体会截断较早的工具调用,将其替换为指向磁盘上文件的指针,减少活跃上下文的大小。
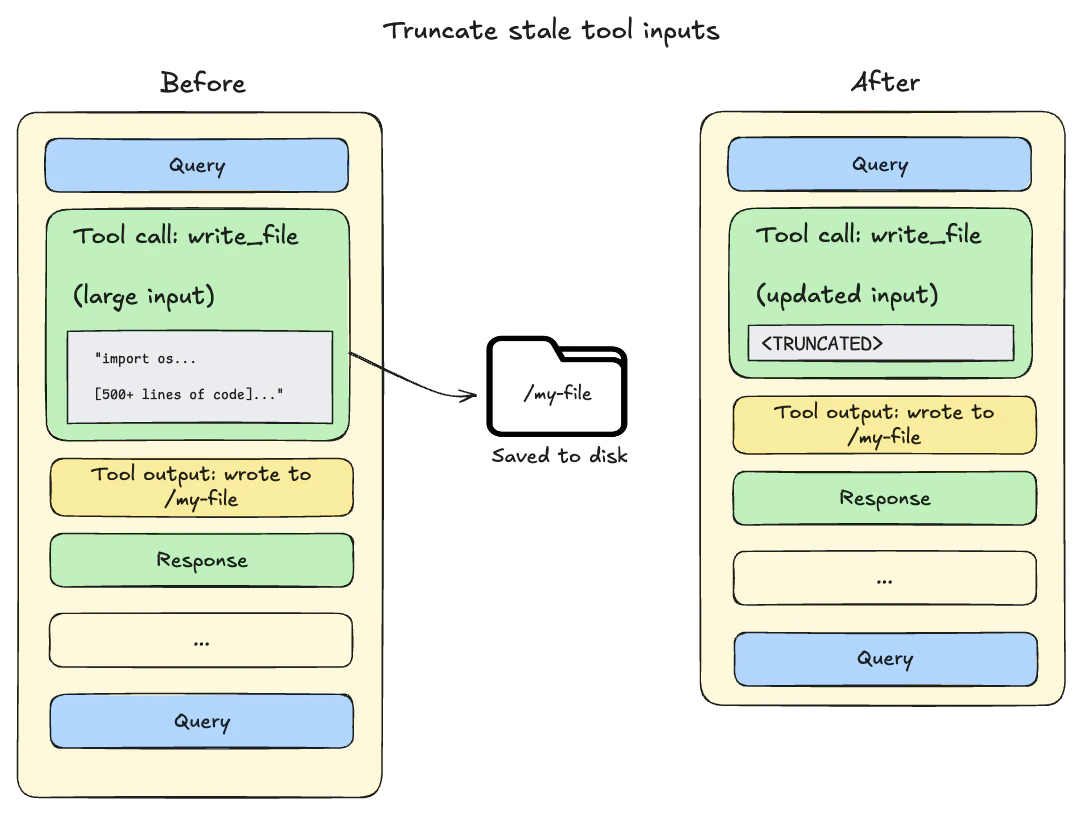
-
工具调用结果超过 20,000 Token:当这种情况发生时,深度智能体将响应卸载到配置的后端,并替换为文件路径引用和前 10 行的预览。智能体随后可以根据需要重新读取或搜索内容。
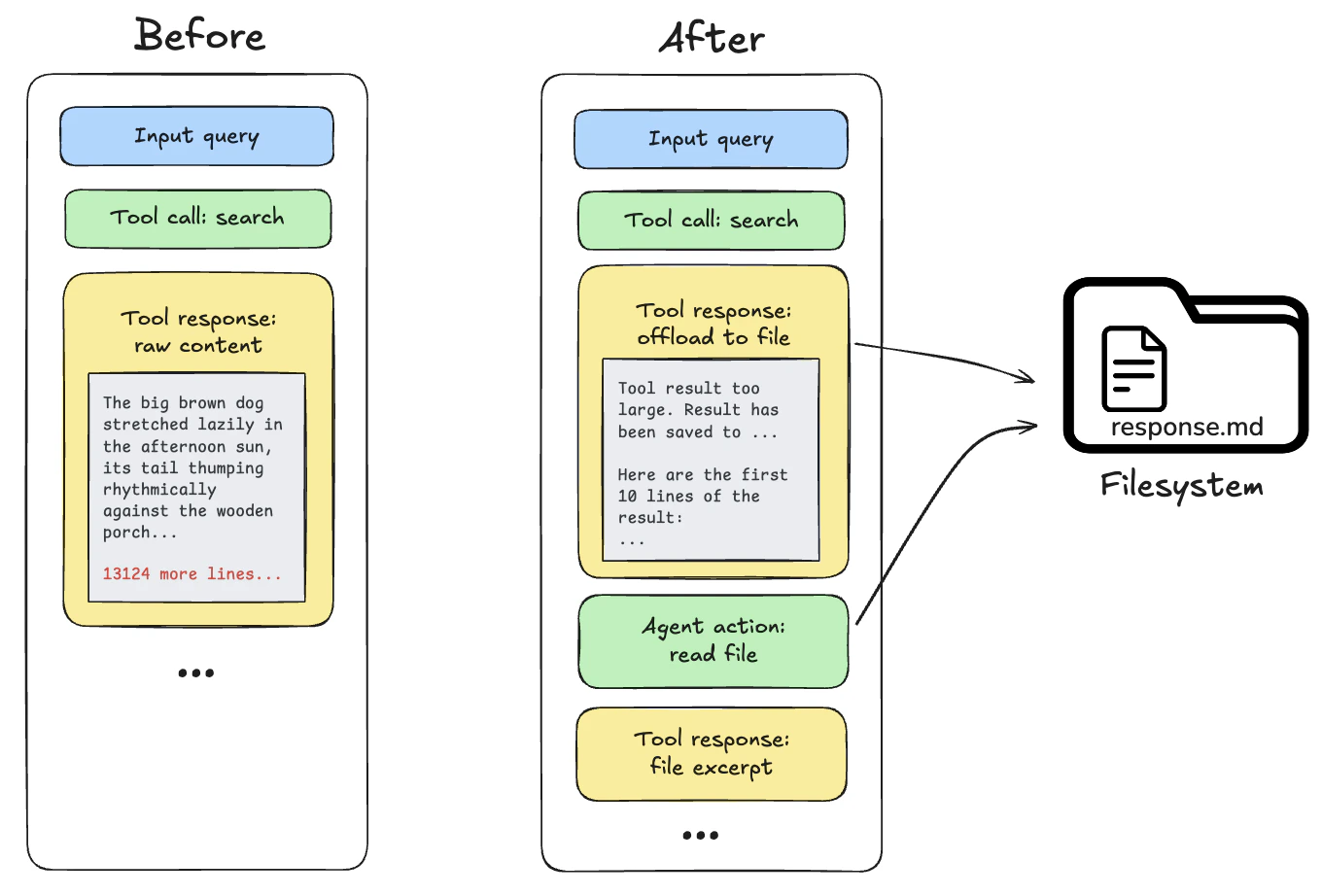
摘要
当上下文大小超过模型的上下文窗口限制(例如max_input_tokens 的 85%),且没有更多上下文适合卸载时,深度智能体会对消息历史进行摘要。
此过程有两个组件:
- 上下文内摘要:大语言模型(LLM)生成对话的结构化摘要,包括会话意图、创建的工件和下一步——替换智能体工作记忆中的完整对话历史。
- 文件系统保留:完整的原始对话消息作为权威记录写入文件系统。
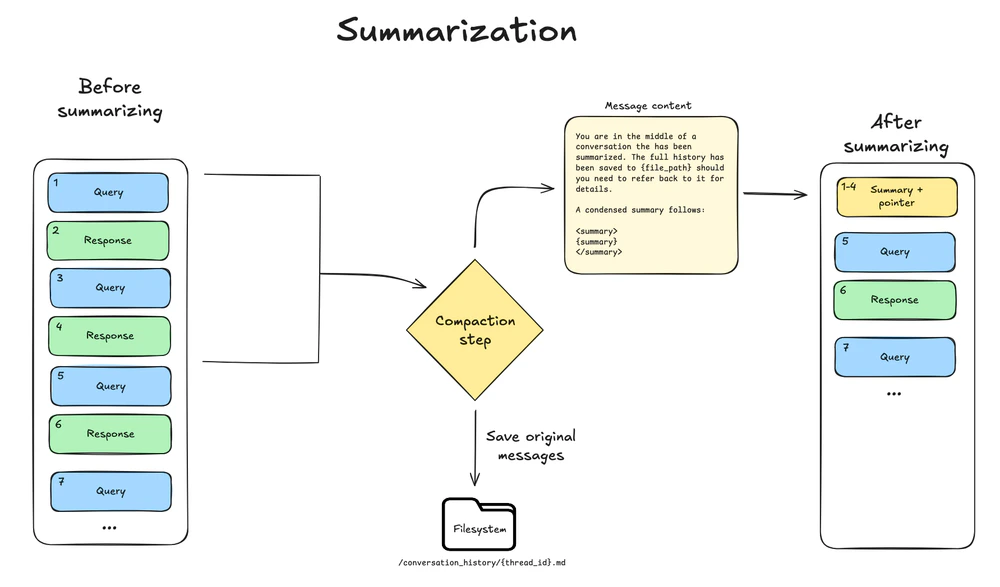
- 在模型 model profile 的
max_input_tokens的 85% 时触发 - 保留 10% 的 Token 作为近期上下文
- 如果模型配置不可用,回退到 170,000 Token 触发 / 保留 6 条消息
- 如果任何模型调用引发标准 ContextOverflowError,深度智能体立即回退到摘要并使用摘要 + 近期保留的消息重试
- 较旧的消息由模型进行摘要
摘要工具
深度智能体包含一个可选的工具用于摘要,使智能体能够在适当的时机触发摘要——例如在任务之间——而不是在固定的 Token 间隔。 你可以通过将其追加到中间件列表来启用此工具:SummarizationToolMiddleware API 参考。
使用子智能体进行上下文隔离
子智能体解决了上下文膨胀问题。当主智能体使用产生大量输出的工具(网络搜索、文件读取、数据库查询)时,上下文窗口会迅速填满。子智能体隔离这些工作——主智能体只接收最终结果,而不是产生结果的数十次工具调用。你还可以独立于主智能体配置每个子智能体(例如模型、工具、系统提示词和技能)。 工作原理:- 主智能体有一个
task工具来委派工作 - 子智能体以自己的全新上下文运行
- 子智能体自主执行直到完成
- 子智能体向主智能体返回单个最终报告
- 主智能体的上下文保持清洁
- 委派复杂任务:对会使主智能体上下文混乱的多步骤工作使用子智能体。
-
保持子智能体响应简洁:指示子智能体返回摘要而非原始数据:
- 使用文件系统存储大量数据:子智能体可以将结果写入文件;主智能体按需读取。
长期记忆
使用默认文件系统时,深度智能体将工作记忆文件存储在智能体状态中,仅在单个线程内持久化。长期记忆使深度智能体能够跨不同线程和对话持久化信息。深度智能体可以使用长期记忆存储用户偏好、累积知识、研究进度或任何应在单个会话之外持久化的信息。 要使用长期记忆,你必须使用CompositeBackend 将特定路径(通常是 /memories/)路由到 LangGraph Store,后者提供持久的跨线程持久化。CompositeBackend 是一个混合存储系统,其中某些文件无限期持久化,而其他文件保持限定在单个线程内。
/memories/ 中填充文件。你提供后端配置、存储和系统提示词指令,告诉智能体保存什么和保存在哪里。例如,你可以提示智能体将偏好存储在 /memories/preferences.txt。路径开始时是空的,当用户分享值得记忆的信息时,智能体使用其文件系统工具(write_file、edit_file)按需创建文件。
要预设记忆,在部署到 LangSmith 时使用 Store API。参见长期记忆了解设置和用例。
最佳实践
- 从正确的输入上下文开始 — 保持记忆最小化用于始终相关的约定;使用专注的技能处理特定任务能力。
- 利用子智能体处理繁重工作 — 委派多步骤、高输出的任务以保持主智能体上下文清洁。
- 在配置中调整子智能体输出 — 如果你在调试时注意到子智能体生成了冗长的输出,可以在子智能体的
system_prompt中添加指导,要求创建摘要和综合发现。 - 使用文件系统 — 将大量输出持久化到文件,使活跃上下文保持较小;模型可以在需要细节时用
read_file和grep拉取片段。 - 记录长期记忆结构 — 告诉智能体
/memories/中有什么以及如何使用它。 - 为工具传递运行时上下文 — 使用
context传递工具需要的用户元数据、API 密钥和其他静态配置。
相关资源
- Harness — 上下文管理概述、卸载、摘要
- 子智能体 — 上下文隔离、运行时上下文传播
- 长期记忆 — 跨线程持久化
- 技能 — 渐进式披露和技能编写
- 后端 — 文件系统后端和 CompositeBackend
- 上下文概念概述 — 上下文类型和生命周期
连接这些文档到 Claude、VSCode 等工具,通过 MCP 获取实时答案。