

LangGraph 内置了持久化层,将图状态保存为检查点。当你使用检查点器编译图时,图状态的快照会在执行的每一步保存,并组织成线程。这实现了人机协作工作流、对话记忆、时间旅行调试和容错执行。Documentation Index
Fetch the complete documentation index at: https://nvd-54.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
智能体服务器自动处理检查点
使用智能体服务器时,你不需要手动实现或配置检查点器。服务器在后台为你处理所有持久化基础设施。
为什么使用持久化
以下功能需要持久化:- 人机协作:检查点器通过允许人类检查、中断和批准图步骤来促进人机协作工作流。这些工作流需要检查点器,因为人员必须能够在任何时间点查看图的状态,并且图必须能够在人员对状态进行任何更新后恢复执行。有关示例,请参阅中断。
- 记忆:检查点器允许在交互之间保持”记忆”。在重复的人类交互(如对话)的情况下,任何后续消息都可以发送到该线程,线程将保留其对先前消息的记忆。有关如何使用检查点器添加和管理对话记忆的信息,请参阅添加记忆。
- 时间旅行:检查点器允许”时间旅行”,允许用户重播先前的图执行以审查和/或调试特定的图步骤。此外,检查点器使得可以在任意检查点分叉图状态以探索替代轨迹。
- 容错:检查点提供容错和错误恢复:如果一个或多个节点在给定的超级步骤中失败,你可以从最后一个成功步骤重新启动图。
- Pending writes: When a graph node fails mid-execution at a given super-step, LangGraph stores pending checkpoint writes from any other nodes that completed successfully at that super-step. When you resume graph execution from that super-step you don’t re-run the successful nodes.
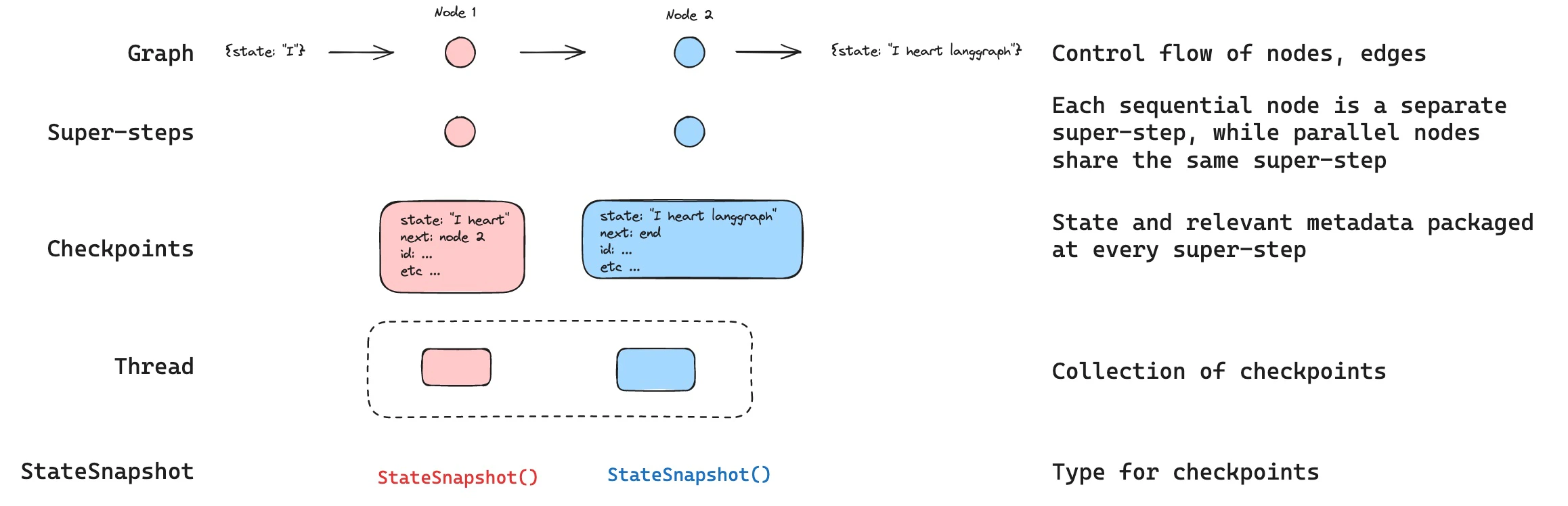
核心概念
线程
线程是分配给检查点器保存的每个检查点的唯一 ID 或线程标识符。它包含一系列运行的累积状态。当运行被执行时,助手底层图的状态将被持久化到线程中。 When invoking a graph with a checkpointer, you must specify athread_id as part of the configurable portion of the config:
thread_id as the primary key for storing and retrieving checkpoints. Without it, the checkpointer cannot save state or resume execution after an interrupt, since the checkpointer uses thread_id to load the saved state.
检查点
线程在特定时间点的状态称为检查点。检查点是在每个超级步骤保存的图状态快照,由StateSnapshot 对象表示(完整字段参考请参阅 StateSnapshot 字段)。
Super-steps
LangGraph creates a checkpoint at each super-step boundary. A super-step is a single “tick” of the graph where all nodes scheduled for that step execute (potentially in parallel). For a sequential graph likeSTART -> A -> B -> END, there are separate super-steps for the input, node A, and node B — producing a checkpoint after each one. Understanding super-step boundaries is important for time travel, because you can only resume execution from a checkpoint (i.e., a super-step boundary).
In addition to super-step checkpoints, LangGraph also persists writes at the node (task) level. As each node within a super-step finishes, its outputs are written to the checkpointer’s checkpoint_writes table as task entries linked to the in-progress checkpoint. These per-task writes are what enable pending writes recovery: if another node in the same super-step fails, the successful nodes’ writes are already durable and don’t need to be re-run on resume. The full state snapshot is then committed once the super-step completes.
LangGraph also persists writes from individual node executions within a super-step. These writes are stored as tasks and used for fault tolerance: if another node in the same super-step fails, successful node writes do not need to be recomputed when you resume. These task writes are not full StateSnapshot checkpoints, so time travel resumes from full checkpoints at super-step boundaries.
Checkpoints are persisted and can be used to restore the state of a thread at a later time.
Let’s see what checkpoints are saved when a simple graph is invoked as follows:
- Empty checkpoint with
STARTas the next node to be executed - Checkpoint with the user input
{'foo': '', 'bar': []}andnodeAas the next node to be executed - Checkpoint with the outputs of
nodeA{'foo': 'a', 'bar': ['a']}andnodeBas the next node to be executed - Checkpoint with the outputs of
nodeB{'foo': 'b', 'bar': ['a', 'b']}and no next nodes to be executed
bar channel values contain outputs from both nodes as we have a reducer for the bar channel.
Checkpoint namespace
Each checkpoint has acheckpoint_ns (checkpoint namespace) field that identifies which graph or subgraph it belongs to:
""(empty string): The checkpoint belongs to the parent (root) graph."node_name:uuid": The checkpoint belongs to a subgraph invoked as the given node. For nested subgraphs, namespaces are joined with|separators (e.g.,"outer_node:uuid|inner_node:uuid").
获取和更新状态
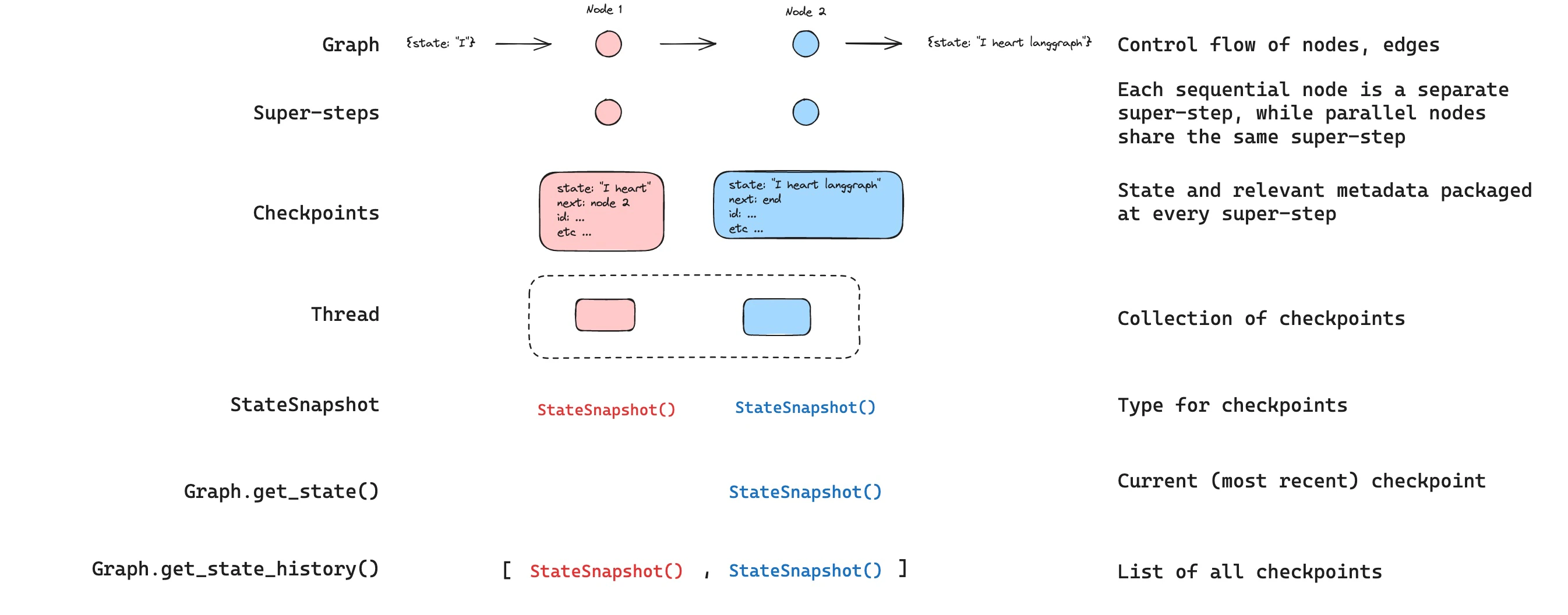
获取状态
When interacting with the saved graph state, you must specify a thread identifier. You can view the latest state of the graph by callinggraph.getState(config). This will return a StateSnapshot object that corresponds to the latest checkpoint associated with the thread ID provided in the config or a checkpoint associated with a checkpoint ID for the thread, if provided.
getState will look like this:
StateSnapshot fields
| Field | Type | Description |
|---|---|---|
values | object | State channel values at this checkpoint. |
next | string[] | Node names to execute next. Empty [] means the graph is complete. |
config | object | Contains thread_id, checkpoint_ns, and checkpoint_id. |
metadata | object | Execution metadata. Contains source ("input", "loop", or "update"), writes (node outputs), and step (super-step counter). |
createdAt | string | ISO 8601 timestamp of when this checkpoint was created. |
parentConfig | object | null | Config of the previous checkpoint. null for the first checkpoint. |
tasks | PregelTask[] | Tasks to execute at this step. Each task has id, name, error, interrupts, and optionally state (subgraph snapshot, when using subgraphs: true). |
获取状态历史
You can get the full history of the graph execution for a given thread by callinggraph.getStateHistory(config). This will return a list of StateSnapshot objects associated with the thread ID provided in the config. Importantly, the checkpoints will be ordered chronologically with the most recent checkpoint / StateSnapshot being the first in the list.
getStateHistory will look like this:
Find a specific checkpoint
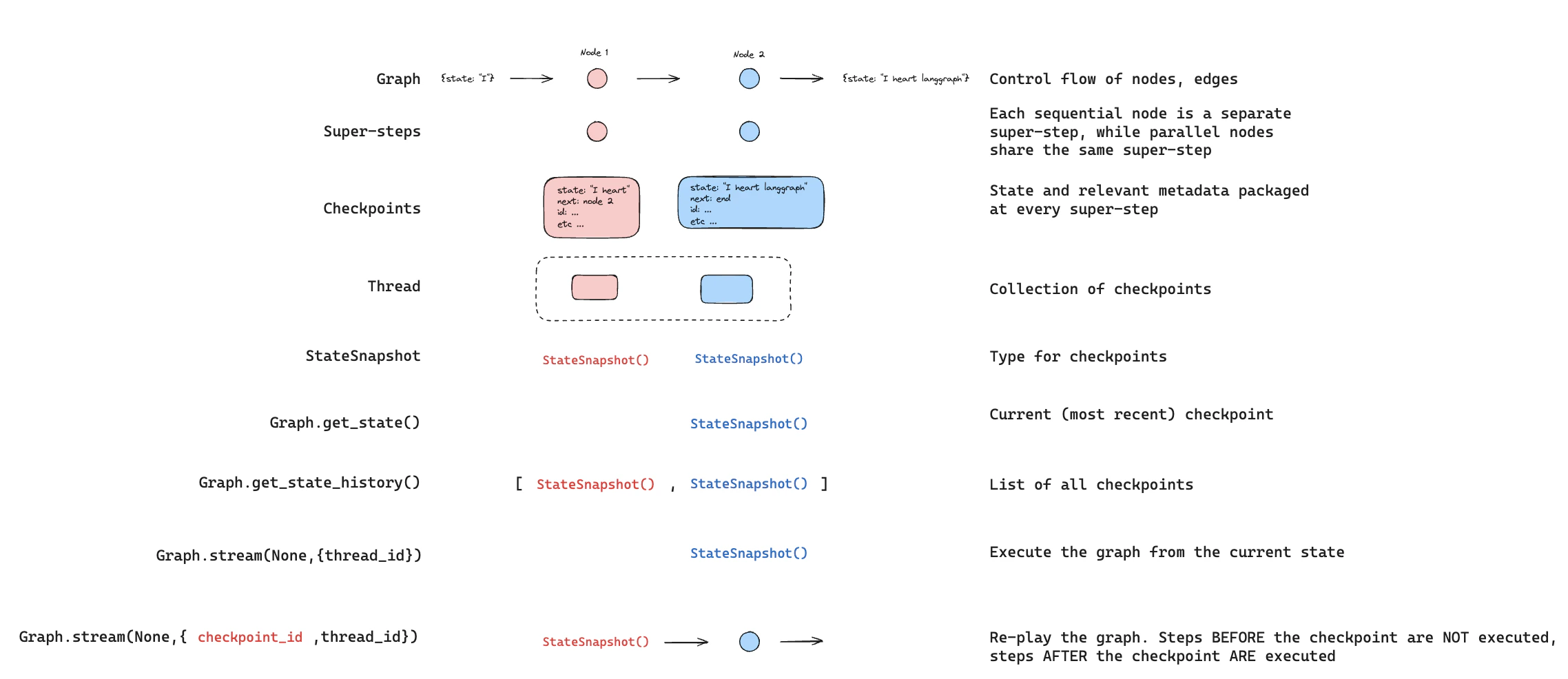
You can filter the state history to find checkpoints matching specific criteria:Replay
Replay re-executes steps from a prior checkpoint. Invoke the graph with a priorcheckpoint_id to re-run nodes after that checkpoint. Nodes before the checkpoint are skipped (their results are already saved). Nodes after the checkpoint re-execute, including any LLM calls, API requests, or interrupts — which are always re-triggered during replay.
See Time travel for full details and code examples on replaying past executions.
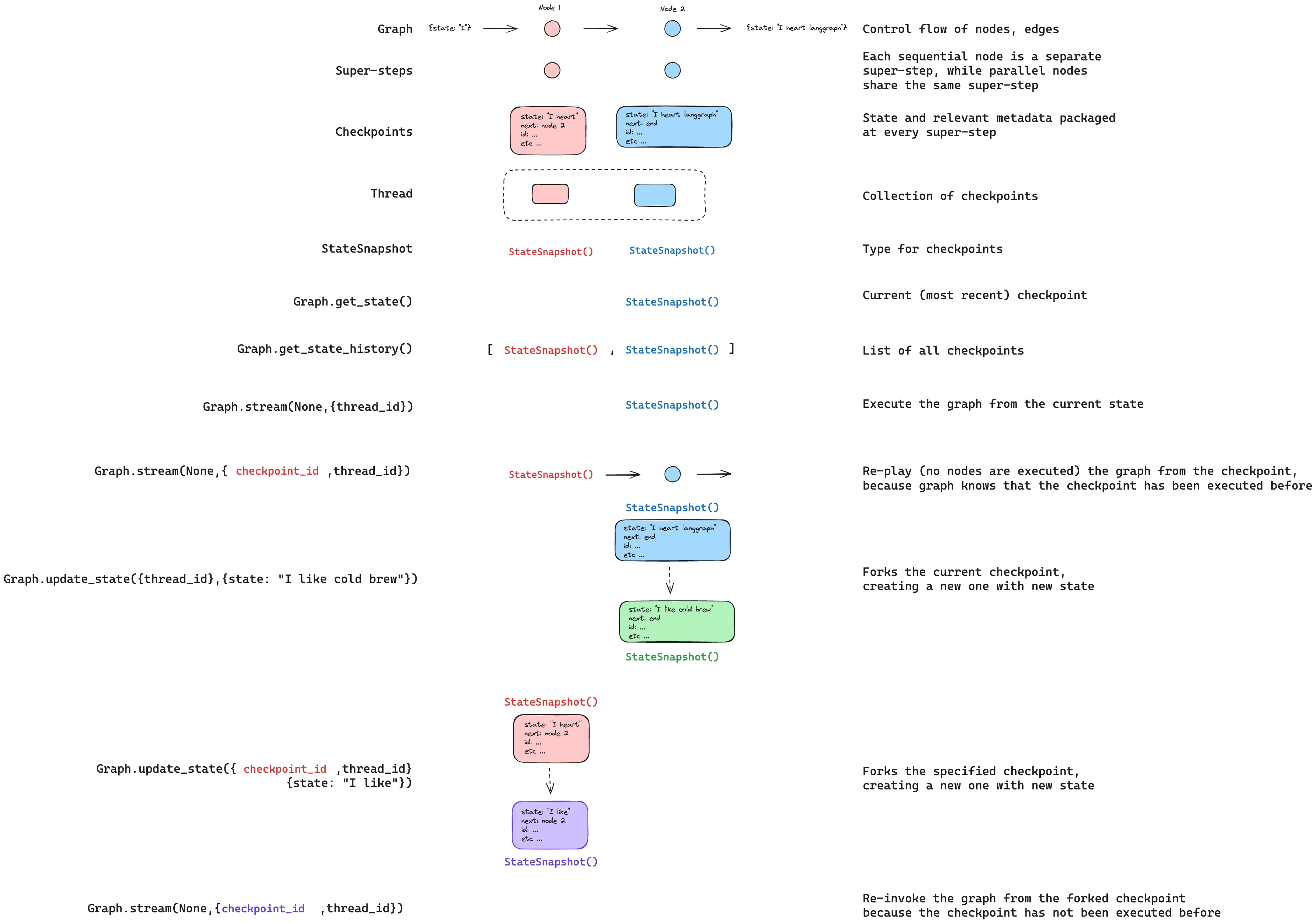
更新状态
You can edit the graph state usinggraph.updateState(). This creates a new checkpoint with the updated values — it does not modify the original checkpoint. The update is treated the same as a node update: values are passed through reducer functions when defined, so channels with reducers accumulate values rather than overwrite them.
You can optionally specify asNode to control which node the update is treated as coming from, which affects which node executes next. See Time travel: asNode for details.
记忆存储
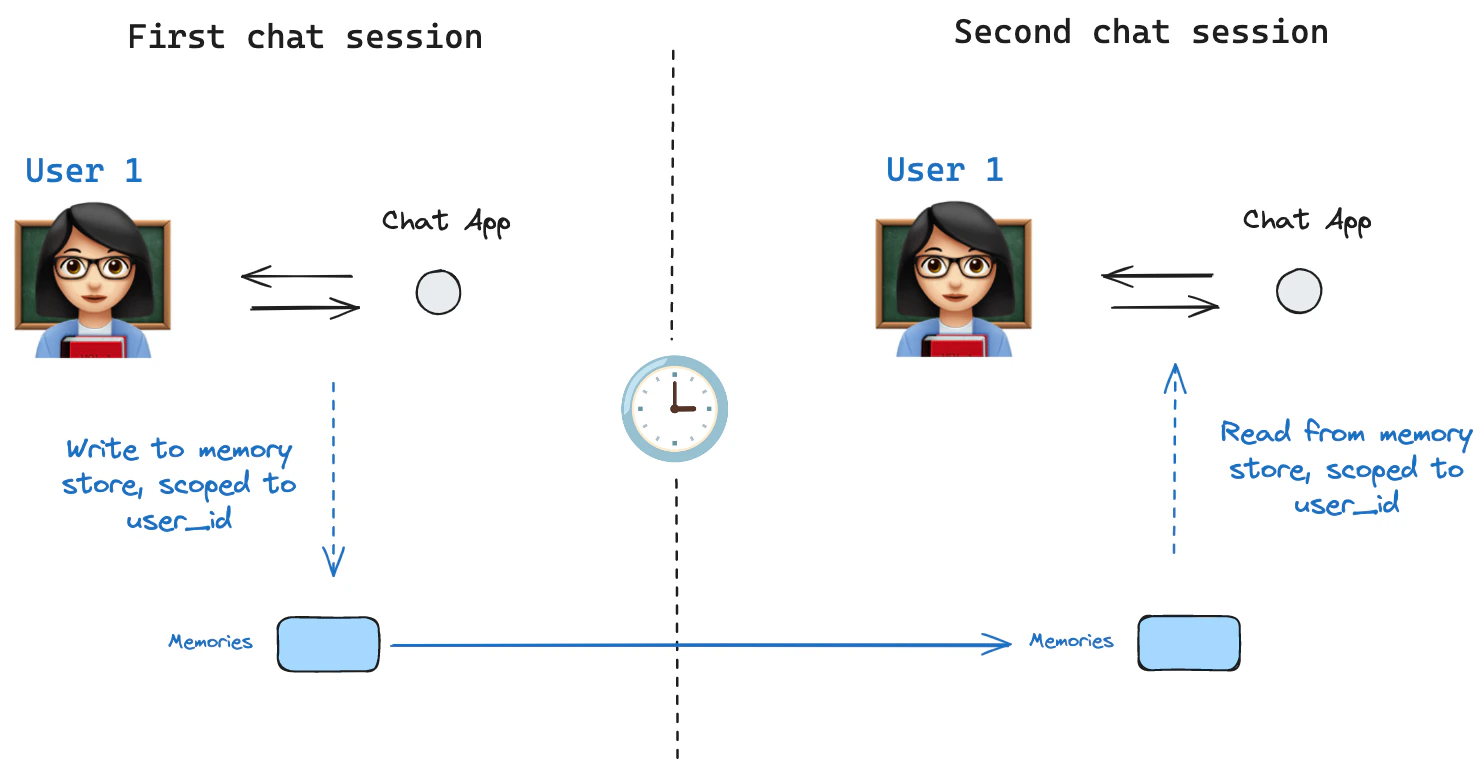
Store interface. As an illustration, we can define an InMemoryStore to store information about a user across threads. We simply compile our graph with a checkpointer, as before, and pass the store.
LangGraph API handles stores automatically
When using the LangGraph API, you don’t need to implement or configure stores manually. The API handles all storage infrastructure for you behind the scenes.
InMemoryStore is suitable for development and testing. For production, use a persistent store like
PostgresStore, MongoDBStore, or RedisStore. All implementations extend BaseStore, which is the type annotation to use in node function signatures.基本用法
First, let’s showcase this in isolation without using LangGraph.tuple, which in this specific example will be (<user_id>, "memories"). The namespace can be any length and represent anything, does not have to be user specific.
store.put method to save memories to our namespace in the store. When we do this, we specify the namespace, as defined above, and a key-value pair for the memory: the key is simply a unique identifier for the memory (memory_id) and the value (a dictionary) is the memory itself.
store.search method, which will return memories for a given user as a list, up to the limit argument (default 10). With InMemoryStore, items are returned in insertion order, so the most recent memory is last in the list; other backends may order differently (see Listing items in a namespace).
-
value: The value of this memory -
key: A unique key for this memory in this namespace -
namespace: A tuple of strings, the namespace of this memory typeWhile the type istuple, it may be serialized as a list when converted to JSON (for example,['1', 'memories']). -
createdAt: Timestamp for when this memory was created -
updatedAt: Timestamp for when this memory was updated
Listing items in a namespace
Callingstore.search with no query and no filter returns the items stored under the namespace prefix, up to limit. Use this to enumerate everything in a namespace when you don’t need semantic ranking.
namespace_prefixmatches by prefix, not exactly.("alice",)also returns items under("alice", "memories"),("alice", "preferences"), and so on. To restrict to a single level, pass the full namespace or filter the returned items client-side onitem.namespace.- Results past
limitare silently truncated. There is no overflow signal—setlimitabove your expected maximum, or paginate withoffset. - Default ordering depends on the store backend.
PostgresStoreandAsyncPostgresStorereturn results ordered byupdated_atdescending (most recently updated first).InMemoryStorereturns results in insertion order (most recently inserted last). Do not rely on a specific order across implementations—sort client-side onitem.updated_atif order matters.
store.listNamespaces:
语义搜索
Beyond simple retrieval, the store also supports semantic search, allowing you to find memories based on meaning rather than exact matches. To enable this, configure the store with an embedding model:fields parameter or by specifying the index parameter when storing memories:
在 LangGraph 中使用
With this all in place, we use thememoryStore in LangGraph. The memoryStore works hand-in-hand with the checkpointer: the checkpointer saves state to threads, as discussed above, and the memoryStore allows us to store arbitrary information for access across threads. We compile the graph with both the checkpointer and the memoryStore as follows.
thread_id, as before, and also with a user_id, which we’ll use to namespace our memories to this particular user as we showed above.
userId in any node with the runtime argument. Here’s how you might use it to save memories:
store.search method to get memories. Recall the memories are returned as a list of objects that can be converted to a dictionary.
user_id is the same.
langgraph.json file. For example:
优化检查点存储
检查点器库
Under the hood, checkpointing is powered by checkpointer objects that conform toBaseCheckpointSaver interface. LangGraph provides several checkpointer implementations, all implemented via standalone, installable libraries.
@langchain/langgraph-checkpoint: The base interface for checkpointer savers (BaseCheckpointSaver) and serialization/deserialization interface (SerializerProtocol). Includes in-memory checkpointer implementation (MemorySaver) for experimentation. LangGraph comes with@langchain/langgraph-checkpointincluded.@langchain/langgraph-checkpoint-sqlite: An implementation of LangGraph checkpointer that uses SQLite database (SqliteSaver). Ideal for experimentation and local workflows. Needs to be installed separately.@langchain/langgraph-checkpoint-postgres: An advanced checkpointer that uses Postgres database (PostgresSaver), used in LangSmith. Ideal for using in production. Needs to be installed separately.@langchain/langgraph-checkpoint-mongodb: An advanced checkpointer (MongoDBSaver) and long-term memory store (MongoDBStore) backed by MongoDB. The store supports cross-thread persistence with optional integrated vector search. Ideal for production use. Needs to be installed separately.@langchain/langgraph-checkpoint-redis: An advanced checkpointer that uses Redis database (RedisSaver). Ideal for using in production. Needs to be installed separately.
检查点器接口
Each checkpointer conforms to theBaseCheckpointSaver interface and implements the following methods:
.put- Store a checkpoint with its configuration and metadata..putWrites- Store intermediate writes linked to a checkpoint (i.e. pending writes)..getTuple- Fetch a checkpoint tuple using for a given configuration (thread_idandcheckpoint_id). This is used to populateStateSnapshotingraph.getState()..list- List checkpoints that match a given configuration and filter criteria. This is used to populate state history ingraph.getStateHistory()
将这些文档连接到 Claude、VSCode 等,通过 MCP 获取实时答案。